Results
One Backbone Across Physics, Robotics & 3D Vision
A single ReLN backbone transfers across tasks with no per-symmetry redesign. Its advantage is largest where
features carry geometric structure that changes with the frame — covariance, uncertainty, and scale
— information that semisimple equivariant models discard.
127×
lower trace-recovery error than Lie Neurons on native $\mathrm{GL}(n)$ system ID
Stable
accuracy on 3D Gaussian splats under arbitrary rotations
11.2×
fewer FLOPs/step than EMLP at matched accuracy
27.8×
faster inference than EMLP on Hamiltonian dynamics
Dynamical Systems
Native $\mathrm{GL}(n)$ System Identification
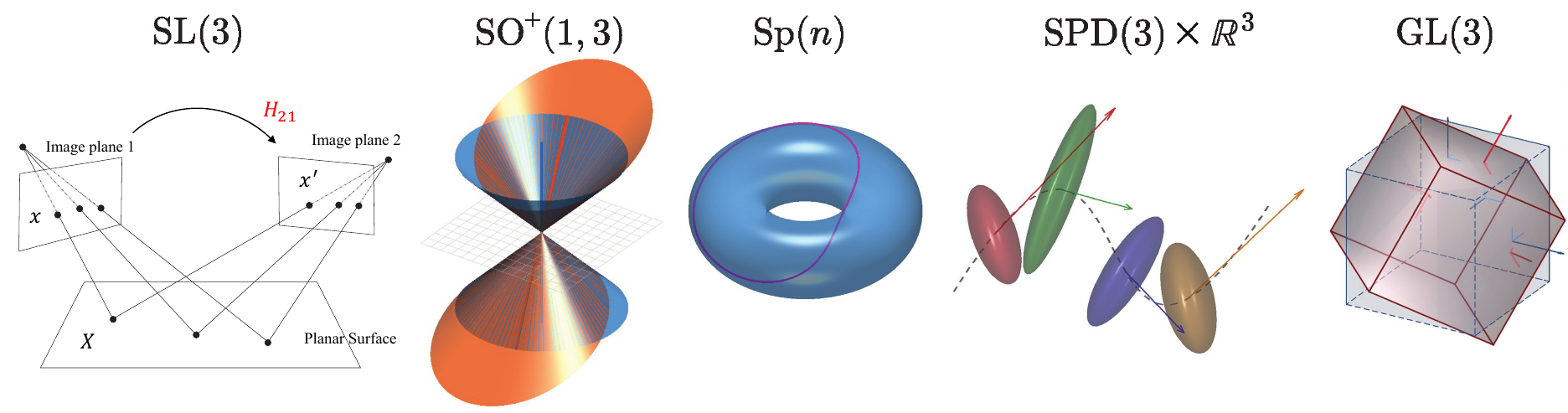
The one task whose symmetry is genuinely the full general linear group. We recover an unknown linear
dynamics matrix $A\in\mathfrak{gl}(3)$ of a system $z_{t+1}=Az_t$ from noisy windowed least-squares estimates.
Under a latent basis change $z\mapsto Sz$ with $S\in\mathrm{GL}(3)$, both inputs and target transform by
similarity $A\mapsto SAS^{-1}$ — the adjoint action on $\mathfrak{gl}(3)$. Crucially, $\mathrm{Tr}(A)$
governs global expansion/contraction and lives in the center, so recovering $A$ needs both the
semisimple ideal and the center. Lie Neurons rely on Killing-form-only invariants that are blind to
$\mathrm{Tr}(A)$ by construction; ReLN's reductive completion recovers it while staying similarity-equivariant.
| Method |
Test split |
Trace MSE ↓ |
Canonical MSE ↓ |
| Baselines |
| Avg-LS | all | 0.0211 | 0.0044 |
| MLP | ID | 0.0145 | 0.0041 |
| MLP | GL | 0.0489 | 0.1480 |
| MLP | GL-Hard | 1.0285 | 57.41 |
| Lie Neurons | all | 1.6850 | 0.0658 |
| Reductive Lie Neurons (Ours) |
| ReLN | all |
0.0133 | 0.0039 |
Mean over 3 seeds. Trace MSE measures center recovery; Canonical MSE measures intrinsic,
similarity-invariant error. Equivariant methods (Avg-LS, Lie Neurons, ReLN) report a single value because they
are exactly similarity-equivariant; the non-equivariant MLP is shown across ID (training basis),
GL (random $S$), and GL-Hard (ill-conditioned $S$), and collapses under unseen basis changes.
Lie Neurons is stable in Canonical MSE but its Trace MSE is two orders of magnitude worse than ReLN
($1.685$ vs. $0.013$). ReLN attains the lowest error on both metrics simultaneously.
Robotics
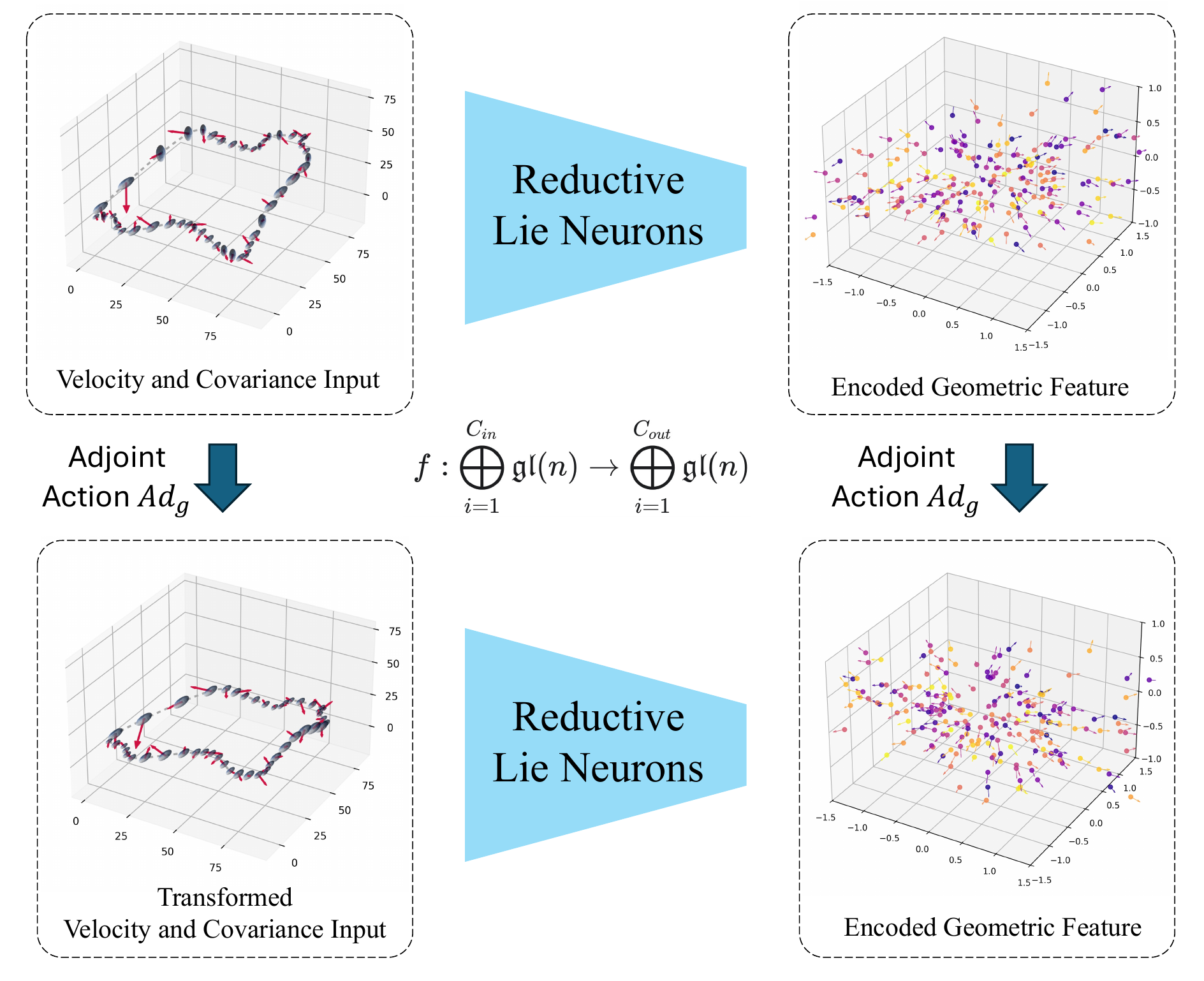
Uncertainty-Aware Drone State Estimation
Reconstructing 3D trajectories from noisy velocities $\mathbf{v}\in\mathbb{R}^3$ and time-varying uncertainty
covariances $C\in\mathrm{SPD}(3)$ requires jointly processing vector and matrix data. ReLNs lift both into a
common $\mathfrak{gl}(3)$ representation; the variant using log-covariance is best, and ReLNs are
exactly invariant to test-time $\mathrm{SO}(3)$ rotations (identical ID and SO(3) metrics).
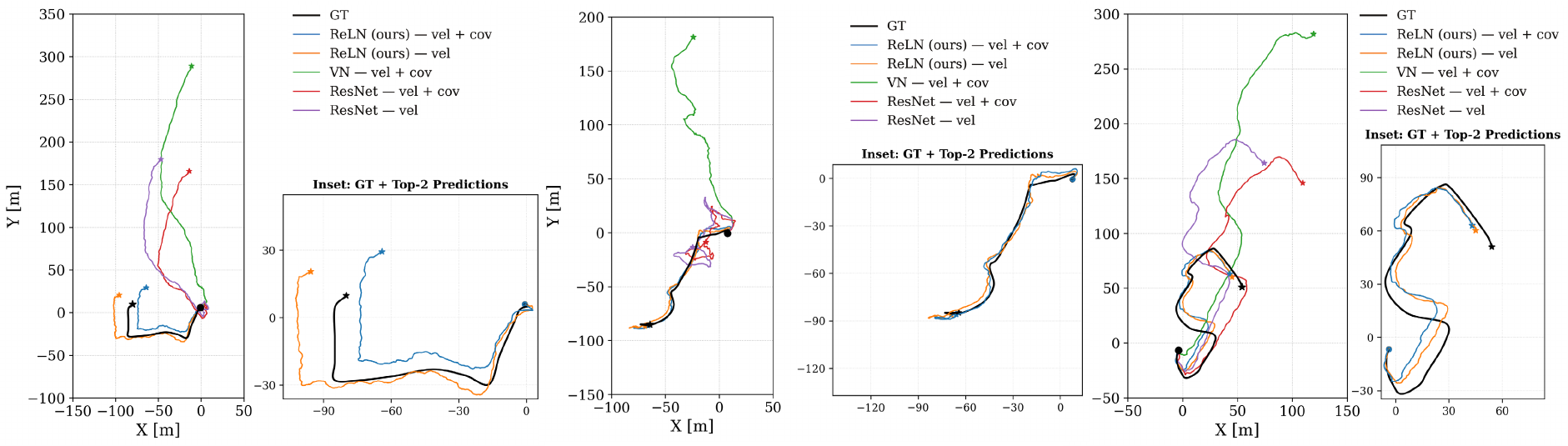
On challenging aggressive trajectories, ReLN variants track the ground truth (black), while the ResNet and
Vector-Neuron baselines shown here drift.
| Model |
Input |
In-Distribution |
SO(3) perturbed |
| ATE ↓ | RTE ↓ | ATE ↓ | RTE ↓ |
|---|
| Non-Equivariant |
| ResNet | $(v, C)$ | 205.11 | 106.07 | 213.26 | 109.37 |
| Equivariant Baselines |
| VN | $v$ | 17.36 | 13.51 | 17.36 | 13.51 |
| VN | $(v, C)$ | 191.78 | 98.39 | 190.22 | 98.26 |
| TFN | $(v, C)$ | 17.56 | 14.40 | 17.56 | 14.40 |
| TFN | $(v, \log C)$ | 16.83 | 13.34 | 16.83 | 13.34 |
| SE(3)-Transformer | $(v, C)$ | 21.67 | 16.77 | 21.67 | 16.77 |
| SE(3)-Transformer | $(v, \log C)$ | 20.12 | 15.36 | 20.12 | 15.36 |
| Lie Neurons | $(v, C)$ | 16.86 | 13.65 | 16.86 | 13.65 |
| Lie Neurons | $(v, \log C)$ | 15.65 | 12.04 | 15.65 | 12.04 |
| Reductive Lie Neurons (Ours) |
| ReLN | $v$ | 16.85 | 12.70 | 16.85 | 12.70 |
| ReLN | $(v, C)$ | 16.49 | 13.02 | 16.49 | 13.02 |
| ReLN | $(v, \log C)$ |
13.92 | 11.04 |
13.92 | 11.04 |
Absolute / relative trajectory error in meters (lower is better).
For a fair comparison, the steerable baselines (TFN, SE(3)-Transformer) and Lie Neurons are given the same
log-covariance interface; ReLN still attains the lowest error. ResNet and VN are reported with their native
inputs (non-equivariant; eigendecomposition-based covariance interface).
3D Vision
Equivariance for 3D Gaussian Splatting
3D Gaussian splats couple a mean $\mu\in\mathbb{R}^3$ with an anisotropic covariance
$\Sigma\in\mathrm{SPD}(3)$ that transform differently under rotation ($R\mu$ vs. $R\Sigma R^\top$). We rebuild
the encoder/decoder of a Gaussian masked-autoencoder with ReLN blocks to enforce $\mathrm{GL}(3)$-equivariance.
The result: classification accuracy on ModelNet10 stays stable under arbitrary rotations where the
baseline collapses, with faster convergence and lower reconstruction error across every attribute.
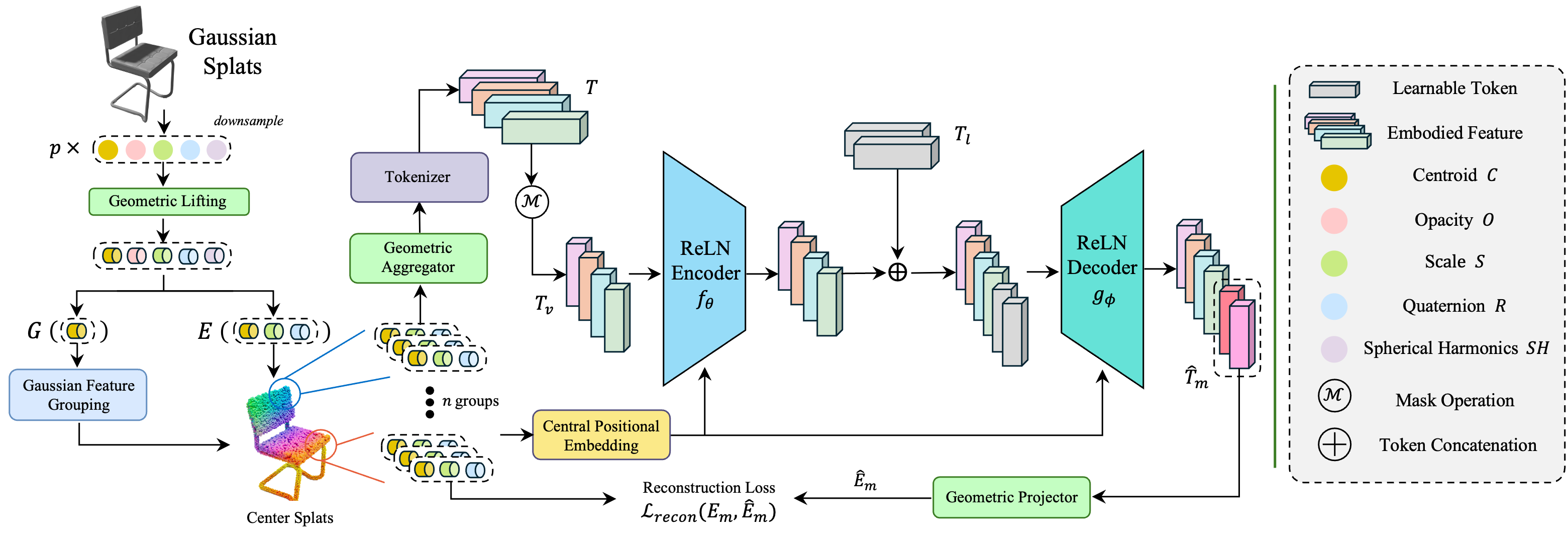
The ReLN-integrated Gaussian-MAE lifts raw splats into $\mathfrak{gl}(3)$, processes active geometry
($\mu,\Sigma$) through a $\mathrm{GL}(3)$-equivariant encoder/decoder, and reconstructs via the Vee map and
bilinear form.
| Method | Standard ↑ | Rotated ↑ |
|---|
| Gaussian-MAE | 93.39 | 18.28 |
| ReLN (Ours) | 94.82 | 95.15 |
ModelNet10 accuracy (%). The baseline drops to 18% under random rotations; ReLN stays at 95%.
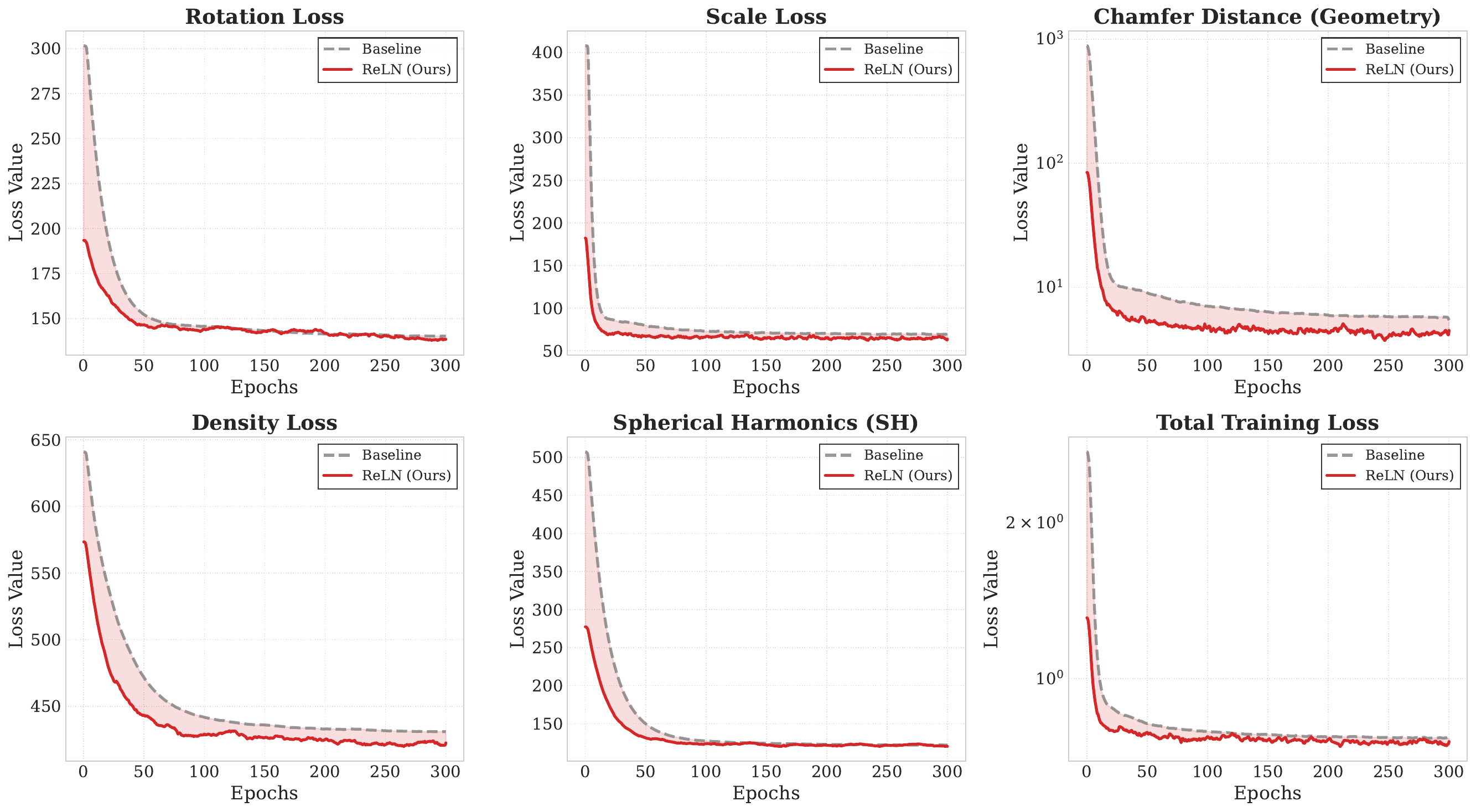
Pre-training on ShapeNet: ReLN (red) reaches lower reconstruction error than the baseline across rotation,
scale, density, SH, and Chamfer distance.
Physics & Efficiency
EMLP Double-Pendulum: Same Accuracy, Far Less Compute
On the EMLP double-pendulum benchmark (Hamiltonian dynamics under $O(2)$, $SO(2)$, $D_6$), ReLN matches or
beats EMLP without any group-specific architecture changes, while running an order of magnitude cheaper.
ReLN uses closed-form matrix operations from exact $\mathrm{Ad}$-equivariant primitives, whereas EMLP relies
on symmetry-dependent basis construction.
| Rollout Error ↓ | EMLP | ReLN |
|---|
| $O(2)$ | 0.012 | 0.011 |
| $SO(2)$ | 0.015 | 0.010 |
| $D_6$ | 0.013 | 0.011 |
| Cost / step | EMLP | ReLN |
|---|
| FLOPs | 1,589,909 | 142,190 |
| Inference (ms) | 61.64 | 2.22 |
ReLN: 11.2× fewer FLOPs and 27.8× faster inference than EMLP at matched accuracy.
Foundations
Algebraic Benchmarks — $\mathfrak{sl}(3)$ & $\mathfrak{sp}(4)$
As a sanity check that the general $\mathfrak{gl}(n)$ construction specializes correctly to semisimple
subalgebras, ReLN matches the specialized Lie Neurons on Platonic-solid classification ($\mathfrak{sl}(3)$,
near-perfect rotated-camera accuracy) and on $\mathfrak{sp}(4)$ invariant-function regression (low MSE and
near-zero invariance error) — while keeping a single, unified architecture across all algebras.